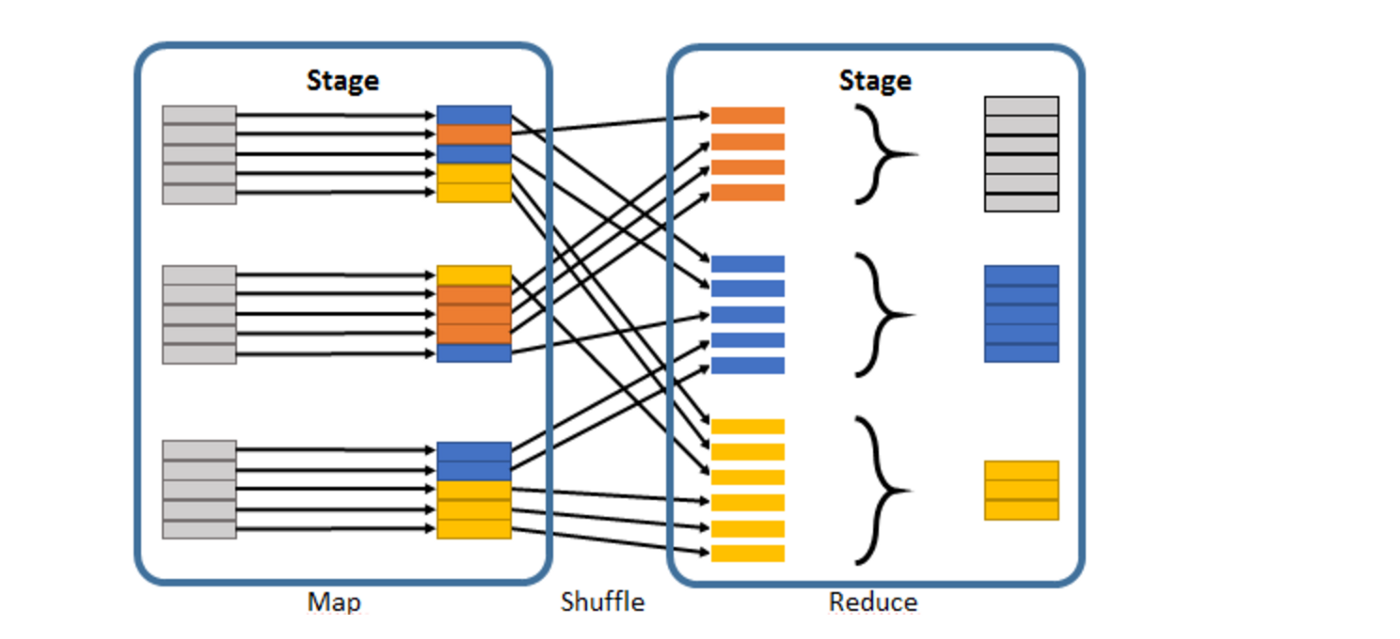
Partitions Number Spark . learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. You do not need to set a proper shuffle partition. what is the default number of spark partitions and how can it be configured? The default number of spark partitions can vary depending on the mode and environment, such as local mode or. this feature simplifies the tuning of shuffle partition number when running queries. For example, if you have 1000 cpu core in your cluster, the. discover the easy steps to retrieve the current number of partitions in a spark dataframe. spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on multiple partitions in parallel. the main abstraction spark provides is a resilient distributed dataset (rdd), which is a collection of elements partitioned across the nodes of the cluster that.
from naifmehanna.com
The default number of spark partitions can vary depending on the mode and environment, such as local mode or. spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on multiple partitions in parallel. learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. You do not need to set a proper shuffle partition. this feature simplifies the tuning of shuffle partition number when running queries. the main abstraction spark provides is a resilient distributed dataset (rdd), which is a collection of elements partitioned across the nodes of the cluster that. For example, if you have 1000 cpu core in your cluster, the. discover the easy steps to retrieve the current number of partitions in a spark dataframe. what is the default number of spark partitions and how can it be configured?
Efficiently working with Spark partitions · Naif Mehanna
Partitions Number Spark You do not need to set a proper shuffle partition. spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on multiple partitions in parallel. learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. You do not need to set a proper shuffle partition. the main abstraction spark provides is a resilient distributed dataset (rdd), which is a collection of elements partitioned across the nodes of the cluster that. this feature simplifies the tuning of shuffle partition number when running queries. what is the default number of spark partitions and how can it be configured? For example, if you have 1000 cpu core in your cluster, the. discover the easy steps to retrieve the current number of partitions in a spark dataframe. The default number of spark partitions can vary depending on the mode and environment, such as local mode or.
From toien.github.io
Spark 分区数量 Kwritin Partitions Number Spark what is the default number of spark partitions and how can it be configured? spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on multiple partitions in parallel. discover the easy steps to retrieve the current number of partitions in a spark dataframe. this feature simplifies the. Partitions Number Spark.
From www.programmersought.com
[Spark2] [Source code learning] [Number of partitions] How does spark Partitions Number Spark For example, if you have 1000 cpu core in your cluster, the. learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. this feature simplifies the tuning of shuffle partition number when running queries. the main abstraction spark provides is a resilient distributed dataset (rdd), which is a collection of elements. Partitions Number Spark.
From towardsdata.dev
Partitions and Bucketing in Spark towards data Partitions Number Spark discover the easy steps to retrieve the current number of partitions in a spark dataframe. this feature simplifies the tuning of shuffle partition number when running queries. You do not need to set a proper shuffle partition. learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. The default number of. Partitions Number Spark.
From www.gangofcoders.net
How does Spark partition(ing) work on files in HDFS? Gang of Coders Partitions Number Spark spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on multiple partitions in parallel. learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. For example, if you have 1000 cpu core in your cluster, the. this feature simplifies the tuning of. Partitions Number Spark.
From sparkbyexamples.com
Spark Partitioning & Partition Understanding Spark By {Examples} Partitions Number Spark spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on multiple partitions in parallel. For example, if you have 1000 cpu core in your cluster, the. learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. what is the default number of. Partitions Number Spark.
From www.turing.com
Resilient Distribution Dataset Immutability in Apache Spark Partitions Number Spark discover the easy steps to retrieve the current number of partitions in a spark dataframe. learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on multiple partitions in parallel. this feature. Partitions Number Spark.
From stackoverflow.com
pyspark Spark number of tasks vs number of partitions Stack Overflow Partitions Number Spark discover the easy steps to retrieve the current number of partitions in a spark dataframe. For example, if you have 1000 cpu core in your cluster, the. learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. The default number of spark partitions can vary depending on the mode and environment, such. Partitions Number Spark.
From best-practice-and-impact.github.io
Managing Partitions — Spark at the ONS Partitions Number Spark You do not need to set a proper shuffle partition. spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on multiple partitions in parallel. discover the easy steps to retrieve the current number of partitions in a spark dataframe. the main abstraction spark provides is a resilient distributed. Partitions Number Spark.
From laptrinhx.com
Determining Number of Partitions in Apache Spark— Part I LaptrinhX Partitions Number Spark You do not need to set a proper shuffle partition. The default number of spark partitions can vary depending on the mode and environment, such as local mode or. the main abstraction spark provides is a resilient distributed dataset (rdd), which is a collection of elements partitioned across the nodes of the cluster that. what is the default. Partitions Number Spark.
From exocpydfk.blob.core.windows.net
What Is Shuffle Partitions In Spark at Joe Warren blog Partitions Number Spark what is the default number of spark partitions and how can it be configured? The default number of spark partitions can vary depending on the mode and environment, such as local mode or. this feature simplifies the tuning of shuffle partition number when running queries. For example, if you have 1000 cpu core in your cluster, the. You. Partitions Number Spark.
From blog.devgenius.io
Spark partitioning. Controlling the number of partitions in… by Amit Partitions Number Spark this feature simplifies the tuning of shuffle partition number when running queries. You do not need to set a proper shuffle partition. The default number of spark partitions can vary depending on the mode and environment, such as local mode or. what is the default number of spark partitions and how can it be configured? learn about. Partitions Number Spark.
From www.youtube.com
Spark Application Partition By in Spark Chapter 2 LearntoSpark Partitions Number Spark this feature simplifies the tuning of shuffle partition number when running queries. what is the default number of spark partitions and how can it be configured? discover the easy steps to retrieve the current number of partitions in a spark dataframe. spark/pyspark partitioning is a way to split the data into multiple partitions so that you. Partitions Number Spark.
From exokeufcv.blob.core.windows.net
Max Number Of Partitions In Spark at Manda Salazar blog Partitions Number Spark the main abstraction spark provides is a resilient distributed dataset (rdd), which is a collection of elements partitioned across the nodes of the cluster that. this feature simplifies the tuning of shuffle partition number when running queries. You do not need to set a proper shuffle partition. discover the easy steps to retrieve the current number of. Partitions Number Spark.
From www.researchgate.net
Processing time of PSLIConSpark as the number of partitions is varied Partitions Number Spark discover the easy steps to retrieve the current number of partitions in a spark dataframe. what is the default number of spark partitions and how can it be configured? this feature simplifies the tuning of shuffle partition number when running queries. You do not need to set a proper shuffle partition. the main abstraction spark provides. Partitions Number Spark.
From sparkbyexamples.com
Spark Get Current Number of Partitions of DataFrame Spark By {Examples} Partitions Number Spark For example, if you have 1000 cpu core in your cluster, the. You do not need to set a proper shuffle partition. this feature simplifies the tuning of shuffle partition number when running queries. what is the default number of spark partitions and how can it be configured? learn about the various partitioning strategies available, including hash. Partitions Number Spark.
From exoocknxi.blob.core.windows.net
Set Partitions In Spark at Erica Colby blog Partitions Number Spark learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. discover the easy steps to retrieve the current number of partitions in a spark dataframe. spark/pyspark partitioning is a way to split the data into multiple partitions so that you can execute transformations on multiple partitions in parallel. You do not. Partitions Number Spark.
From sparkbyexamples.com
Get the Size of Each Spark Partition Spark By {Examples} Partitions Number Spark the main abstraction spark provides is a resilient distributed dataset (rdd), which is a collection of elements partitioned across the nodes of the cluster that. this feature simplifies the tuning of shuffle partition number when running queries. You do not need to set a proper shuffle partition. what is the default number of spark partitions and how. Partitions Number Spark.
From www.jowanza.com
Partitions in Apache Spark — Jowanza Joseph Partitions Number Spark learn about the various partitioning strategies available, including hash partitioning, range partitioning, and custom partitioning, and. this feature simplifies the tuning of shuffle partition number when running queries. You do not need to set a proper shuffle partition. For example, if you have 1000 cpu core in your cluster, the. The default number of spark partitions can vary. Partitions Number Spark.